| 背景 |
突然ですがこの会誌、今年からデジタル編集になりました。そもそも編集者の主な仕事は、提出された紙原稿の管理・掲載順の決定・ページ番号の入力・目次やあとがきの作成といったことです。そして原稿自体はワープロソフトなどで作成するのですが、編集過程でアナログ(手書きでページ番号入れなど)を経るので、どうにも見栄えが悪くなってしまうわけです。その点最終的な出力までをデジタルで行えば、きれいな出力を得られてなおかつスクリプトによる一括処理が可能、さらにデジタルデータなので原稿の管理が簡単になるなど、多くの利点があります。
……というのは建前で、単に僕が「ヤダヤダ! デジタル編集じゃなきゃヤダー!」って駄々こねただけです。いやほら、編集方法をマニュアル化すれば誰でも手軽に編集できるし。編集時間も短縮されるし。とりあえず試してみて、ダメだったらいつも通りの編集にしましょってことに。
| 編集に使うもの |
とりあえず決めていた事がいくつかあって
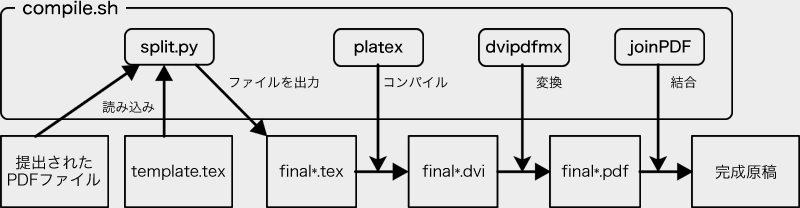
| 編集手順 |
具体的なプロセスは以下のようにしました。
#!/bin/sh
#split.pyの実行
echo "Split PDF files..."
python split.py > /dev/null
echo --------
#分割したPDFファイルをPSファイルに変換
for file in $(ls *_page*.pdf)
do
echo "${file} -> ${file%pdf}ps"
pdftops ${file}
done
echo --------
#TeXファイルをDVIファイルにコンパイル
for file in $(ls final[0-9]*.tex)
do
echo "${file} -> ${file%tex}dvi"
platex ${file} > /dev/null
done
echo --------
#DVIファイルをPDFファイルに変換
for file in $(ls final[0-9]*.dvi)
do
#ファイルの存在を確認してから出力
if ! (test -f ${file%dvi}pdf);
then
echo "${file} -> ${file%dvi}pdf"
dvipdfmx ${file} > /dev/null 2> /dev/null
fi
done
echo --------
rm *_page*.pdf -f
rm *.ps -f
#PDFファイルを結合
echo "Create 68kaisi.pdf..."
joinPDF 68kaisi.pdf `/bin/ls final*.pdf|sort` > /dev/null
rm final* -f
|
# -*- coding:eucjp -*-
import os
import re
class kaishi:
#指定語尾で終わっているファイルのリストを返す
def findfilebyext(self,list,ext):
ret=[]
for x in list:
if x.endswith(ext):
ret.append(x)
return ret
#splitコマンドをforkして呼ぶ
def split(self,pdffile):
pid=os.fork()
if(pid==0):
os.execlp("splitPDF","splitPDF",pdffile);
state=os.wait();
print state #終了コードあるのかな?
#指定した正規表現にマッチするファイルの数を返す
def countfilebyregexp(self,list,regexp):
ret=0
for x in list:
m=re.compile(regexp).search(x)
if m!=None and m.start()==0:
ret=ret+1
return ret
#指定ディレクトリの中のファイルだけを取りだす
def listfile(self,rootpath):
files=os.listdir(rootpath)
dirlist=[]
for x in files:
if os.path.isfile(x):
dirlist.append(x)
return dirlist
#テンプレを読み込む
def loadtemp(self,file):
f=open(file,"r")
ret=f.read();
f.close()
return ret;
#ヘッダのテンプレを得る
def loadheadertemp(self,file):
f=open(file,"r")
headtemp=[]
while 1:
cat=f.readline()[:-1];
#print "--------------------------------"+cat
if not cat:
break;
left=f.readline()[:-1];
right=f.readline()[:-1];
headtemp.append([cat,[left,right]]);
f.close()
return headtemp; #ヘッダーリストを返す
#ファイルを保存する
def savefile(self,file,data):
f=open(file,"w")
f.write(data);
f.close()
return
def findkeyheader(self,headers,kind):
for x in headers:
print x
if x[0]==kind:
return x[1]
#テンプレを元にファイルを構築
def makefinalpage(self,name,page,kind,temp,headers):
temp=temp.replace("##pdfname##",name)
temp=temp.replace("##page##",str(page))
print "------------"+kind
hl=self.findkeyheader(headers,kind)[0]
hr=self.findkeyheader(headers,kind)[1]
if hl=="":
temp=temp.replace("##headright##",r"\renewcommand{\headrulewidth}{0pt}");
else:
temp=temp.replace("##headright##",r"\fancyhead[RO]{"+ hl+"}")
if hr=="":
temp=temp.replace("##headleft##",r"\renewcommand{\headrulewidth}{0pt}")
else:
temp=temp.replace("##headleft##",r"\fancyhead[LE]{"+hr+"}")
return temp
def chgoutno(self,no):
ret=no;
b=[2,3,4,1]
ret=b[(no-1)%4]+(no-1)/4*4
return ret
##コンストラクタですべてやってしまう無意味さ
def __init__(self):
temp=self.loadtemp("template.tex") #テンプレを読み込む
headers=self.loadheadertemp("headertemplate.tex");
rootpath="."
createdir="final"
startpage=1;
dirlist=self.listfile(rootpath)
pdffiles=self.findfilebyext(dirlist,".pdf");
pdffiles.sort();
print (pdffiles) #処理するファイルをGet順番もOK
pagekind=""
for x in pdffiles:
self.split(x)
dirlist=self.listfile(rootpath)
pdffiles=self.findfilebyext(dirlist,".pdf");
cnt=self.countfilebyregexp(pdffiles,x[:-4]+"_page[0-9]+\.pdf");
print "-------------"
print cnt
print x[:-4]
print "-------------"
pagekind=x[3]; #種類を得る
ext='';
for y in range(cnt+1)[1:]:
if x[-5]=='2':
ext='.pdf'
elif x[-5]=='3':
ext='.pdf'
print os.spawnlp(os.P_WAIT,'cp','cp',x[:-4]+"_page"+str(y)+'.pdf','final%03d.pdf' % self.chgoutno(startpage))
else:
ext='.ps'
data=self.makefinalpage(x[:-4]+"_page"+str(y)+ext,startpage,pagekind,temp,headers)
self.savefile("final"+"%03d" % self.chgoutno(startpage)+".tex",data)
startpage=startpage+1
kaishi()
|
\documentclass[a4paper,twoside]{jsarticle}
\usepackage{mediabb}
\usepackage[dvipdfm]{graphicx}
\usepackage{fancyhdr}
% 背景に画像を貼るための設定
\makeatletter
\let\@@shipout\shipout\def\shipout
\vbox{\@@shipout\vbox\bgroup\afterassignment\insertBackGround\let\reserved@a=}
\def\insertBackGround#1{#1%
\iftombow\copy\BackGround\kern0pt
\else\kern-1truein\moveleft1truein\copy\BackGround\kern1truein
\fi}
\newbox\BackGroundUnit
\newbox\BackGround
\setbox\BackGroundUnit\hbox{\includegraphics*{##pdfname##}}
\@tempdima\paperheight
\advance\@tempdima\ht\BackGroundUnit\advance\@tempdima\dp\BackGroundUnit
\setbox\BackGround
\vbox to \@tempdima{
\@tempdima=\paperwidth\advance\@tempdima\wd\BackGroundUnit
\leaders\hbox to\@tempdima{\leaders\copy\BackGroundUnit\hfil}\vfil}
\wd\BackGround=0pt\ht\BackGround=0pt\dp\BackGround=0pt
\makeatother
% マージンの設定
\setlength{\topmargin}{12mm}
\addtolength{\topmargin}{-1in}
\setlength{\oddsidemargin}{15mm}
\addtolength{\oddsidemargin}{-1in}
\setlength{\evensidemargin}{15mm}
\addtolength{\evensidemargin}{-1in}
% 本文領域の大きさの設定
\textwidth 180mm
\textheight 250mm
% ページ番号の書式の設定
\renewcommand{\thepage}{{\large \arabic{page}}}
% ヘッダ・フッタ内容の設定
\pagestyle{fancy}
\fancyhead{}
\fancyfoot{}
##headright##
##headleft##
\fancyfoot[RO,LE]{\thepage}
% ヘッダの長さを調整
\addtolength{\headwidth}{-125mm}
\addtolength{\oddsidemargin}{125mm}
\addtolength{\evensidemargin}{-125mm}
% 本文領域
\begin{document}
\setcounter{page}{##page##}
\mbox{}\newpage
\end{document}
|
| 仕様とか |
| 最後に |
今回要求されたことは「不特定数のPDFファイルにページ番号をいれて1つのファイルにまとめる」という非常に限定的なケース、どっちかというと内輪向けで、この文章を読んでも得るものなんてあんまり……というか全然無いかもしれません。ですが割と役に立つキーワードなんかもある(かもしれない)と思うんで、気になった言葉があったら調べてみてください。LaTeXやシェルスクリプトなんかはとても便利なので、とりあえず使ってみると面白いと思います。